
A Comprehensive Guide to Blockchain Oracles
Introduction
Blockchain technology is revolutionary—it allows us to record and utilize information in a decentralized, transparent, and immutable way.
However, blockchains are inherently isolated from the real world. Without access to external data, blockchain networks remain limited and Web3 applications cannot reach their full potential. So, how do we get real-world information onchain?
Blockchain oracles are gateways between the real world and blockchain ecosystems, enabling external data to flow onchain. This critical connection powers a wide range of applications, from crypto and DeFi to prediction markets, insurance, gaming, and beyond.
In this guide, we’ll dive deeper into why blockchains need oracles, explore different oracle solutions, and learn why UMA is ideal for intersubjective data.
Key Takeaways
Blockchain oracles connect web3 apps with real-world data. Blockchain oracles are essential tools that connect isolated blockchain networks to external data, enabling dApps to access real-world information for diverse applications like DeFi, prediction markets, insurance, and gaming.
Four types of data managed by oracles. Crypto oracles handle objective data (factual and measurable), subjective data (opinion-based), intersubjective data (community consensus), and random data (unpredictable and fair outcomes), each tailored for specific blockchain applications.
Decentralized oracles ensure scalability, security, and trust. Decentralized oracles mitigate risks like single points of failure and data manipulation, providing a secure and scalable framework for smart contracts to operate in a trustless environment.
UMA’s oracle leads in verifying intersubjective data. It uses a cost-efficient, dispute-driven model to verify data requiring community consensus, making it ideal for prediction markets, decentralized governance, and more nuanced use cases.
The future of oracles: beyond prediction markets. The growing demand for intersubjective data verification opens new possibilities in applications like decentralized fact-checking, reputation systems, media moderation, and collaborative decision-making, signaling oracles’ transformative role in Web3.
Why Blockchains Need Oracles
Blockchains are built on the principle of immutability—once data is written onchain, it cannot be altered. This is a powerful feature that ensures integrity and transparency. However, the onchain world is also trustless and permissionless, meaning anyone can contribute information. This creates a high demand for reliable, tamper-proof data.
So, in a permissionless world where anyone can write anything onchain, how do we ensure accurate and valid data gets published onchain? This is why blockchains need oracles.
The Oracle Problem
While blockchains are exceptionally secure within their own environments, they are inherently designed as closed systems. This unique design is optimal for security but limits onchain environments from accessing external data directly, leaving them “blind” to the outside world.
For dApps that depend on external data, such as asset prices, sports results, the outcome of a global event, or even weather events, this isolation becomes a significant roadblock and creates a potential single point of failure for many applications. This challenge is known as the oracle problem.
Solving The Oracle Problem
Solving the oracle problem requires finding a way to connect blockchains with offchain data and enabling dApps to access real-world information for more dynamic and relevant functionality.
Inbound oracles feed external data, such as sports scores or asset prices, into blockchains, enabling smart contracts to react to real-world events.
Outbound oracles, on the other hand, send data from blockchains to external systems, such as triggering a payment through an external API after a smart contract condition is met.
Centralized Oracles vs. Decentralized Oracles
Centralized and decentralized oracles differ primarily in how they source and verify data for blockchain applications.
Centralized oracles rely on a single entity or provider to deliver offchain data to smart contracts. While they are simpler to implement, they pose significant risks, such as a single point of failure, vulnerability to tampering, and reliance on trust in the central entity, which undermine the trustless and decentralized nature of blockchain applications.
Decentralized oracles aggregate data from multiple independent sources to ensure accuracy and reduce the risk of manipulation. They use mechanisms like consensus or cryptographic proofs to validate information before delivering it onchain, aligning with the trustless and permissionless nature of blockchains. While decentralized oracles are more robust and secure, they may involve higher costs and complexity compared to centralized counterparts.
Hardware oracles, which rely on physical devices to bring real-world data onchain, are another approach but can introduce vulnerabilities if the hardware is tampered with or compromised. Hence, decentralized oracles are widely used amongst dApps and smart contracts that rely on access to external data.
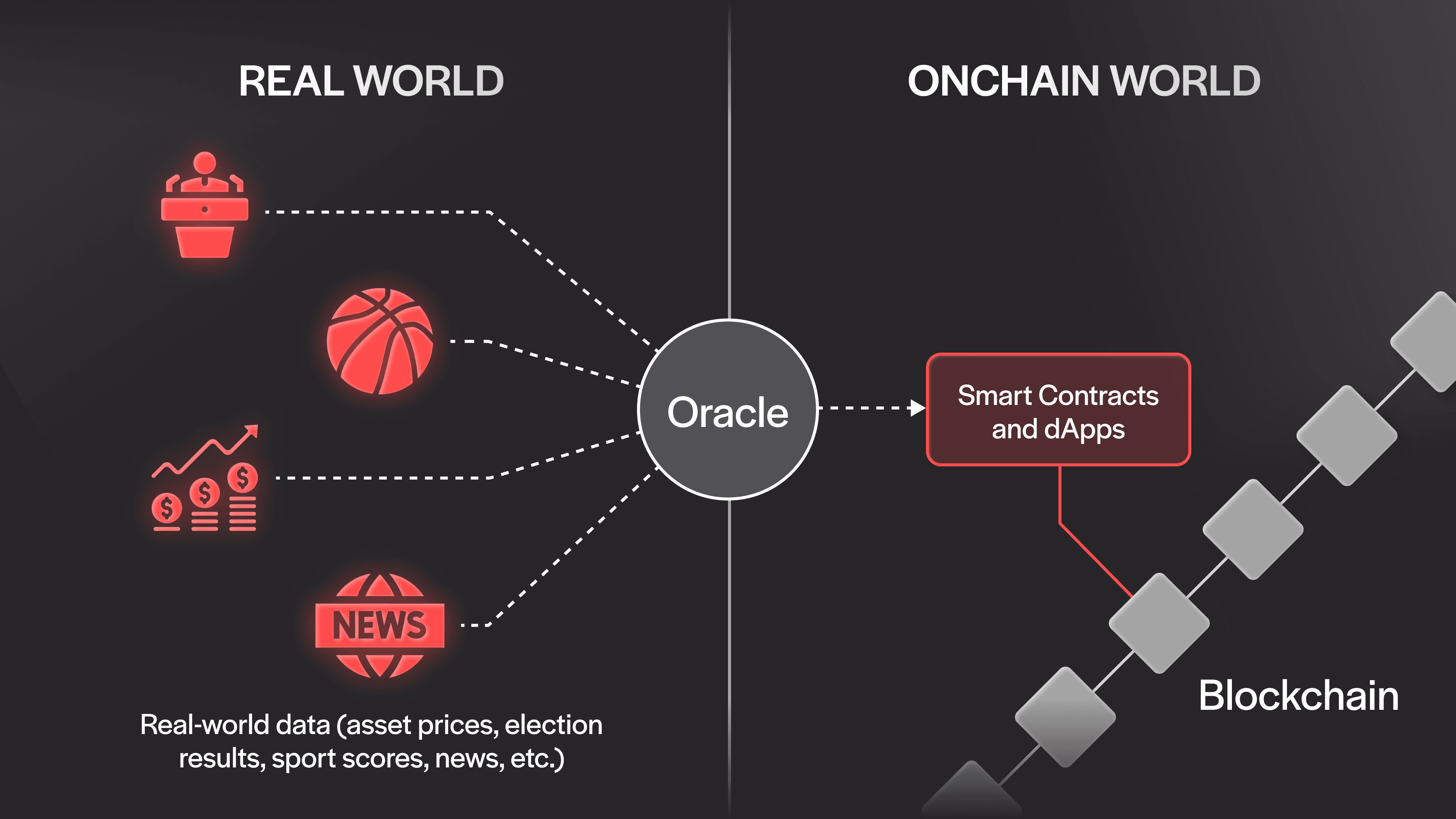
How Blockchain Oracles Interact with Smart Contracts
Blockchain oracles connect smart contracts with external data, enabling blockchain-based applications to deliver real-world utility to end-users. Smart contracts are deterministic by design, meaning they can only execute based on the information available within the blockchain. Crypto oracles expand their capabilities by providing offchain data, empowering dApps to operate dynamically and meaningfully.
Smart contracts rely on oracles to bring in trusted offchain inputs and even send outputs to external systems through inbound oracles and outbound oracles.
Here’s how oracles enable these types of interactions:
Data Requests: Smart contracts submit a request for external data, such as asset prices or event outcomes, specifying parameters like time frames or collateral.
Data Gathering: The oracle collects this information from data providers, APIs, or hardware oracles, ensuring accuracy and reducing the risk of reliance on centralized sources.
Data Submission: Once verified, the oracle delivers the data onchain, where the smart contract evaluates it to trigger actions like executing trades or settling transactions.
Dispute Resolution: In decentralized systems like UMA, disputed data can escalate to consensus-based verification mechanisms, ensuring integrity and trust.
Action Execution: Inbound oracles feed data into smart contracts to enable decisions, while outbound oracles send instructions to external systems, such as triggering payments or updating APIs.
These seamless interactions expand the functionality of smart contracts, empowering applications for crypto, DeFi, gaming, insurance, and beyond. By enabling reliable data exchange, oracles ensure that blockchain ecosystems can integrate and interact with the real world securely and efficiently.
The Four Types of Data that Oracles Handle
To understand the power of oracles, it’s crucial to explore the types of data they can bring onchain. Not all data is created equal—different applications require different types of information, each with its own use cases and challenges. Let’s examine the main types of data that oracles manage along with some examples.
Objective Data
Objective data is factual and measurable information that is universally verifiable and can be directly consumed by smart contracts to power their functionality, without requiring interpretation or consensus. This type of data is straightforward, quantitative information that does not change regardless of interpretation or opinion. It is often used in applications that require high precision, such as financial data, weather conditions, and sports scores.
Example: Universally verifiable facts such as financial asset prices (e.g., the ETH/USD exchange rate), meteorological data (e.g., current temperature in Tokyo), and final sports scores (e.g., the score of a basketball game).
Subjective Data
Subjective data is information that depends on personal opinions, preferences, or interpretations, often used in contexts where individual perspectives are valued. This type of data may vary significantly between different users or groups. It is often utilized in user-generated content or situations where feedback, sentiment, or preferences matter.
Example: Opinion based information such as user ratings (e.g., a 5-star rating for an app), product reviews, sentiment analysis on social media, survey responses, and opinion polls on preference-based topics (e.g. favorite movie or brand preference).
Intersubjective Data
Intersubjective data is information that doesn't have a single, clear-cut answer but instead relies on the collective agreement or consensus of a group. In other words, it's data where the “truth” is determined by what most people agree upon, rather than hard measurable facts.
Example: Consensus-driven data prompted by questions like: Did a sporting event get canceled due to bad weather conditions? When a politician says “the wall,” are they referring to the border wall or their bedroom wall? How many followers does someone need on social media to be considered famous? Is a new song considered a top hit?
Random Data
Random data is information that is generated in an unbiased, unpredictable way, often necessary for applications where fairness and randomness are required. This type of data ensures that outcomes cannot be influenced or manipulated. It is commonly used in gaming, lotteries, and any applications needing secure randomness for fair participation.
Example: Unpredictable data such as lottery draws, character selection in video games, and cryptographic key generation for security applications.

Although all four of these data types serve their fair share of use cases, we’ve witnessed an explosion of interest in intersubjective data and solutions that can process and verify it onchain—and this trend is only getting started.
The Growing Importance of Verifying Intersubjective Data
While oracles handle a variety of data types, each with its own unique applications, one type of data has grown increasingly important: intersubjective data.
Unlike objective or random data, intersubjective data requires community consensus, making it particularly challenging to verify in decentralized environments. Traditional oracles excel at delivering objective data, like asset prices or weather conditions, where there’s little room for interpretation. In contrast, intersubjective data is inherently ambiguous, requiring input from multiple stakeholders to reach a consensus. With this said, the ability to process intersubjective data can unlock new possibilities and use cases on a grand scale.
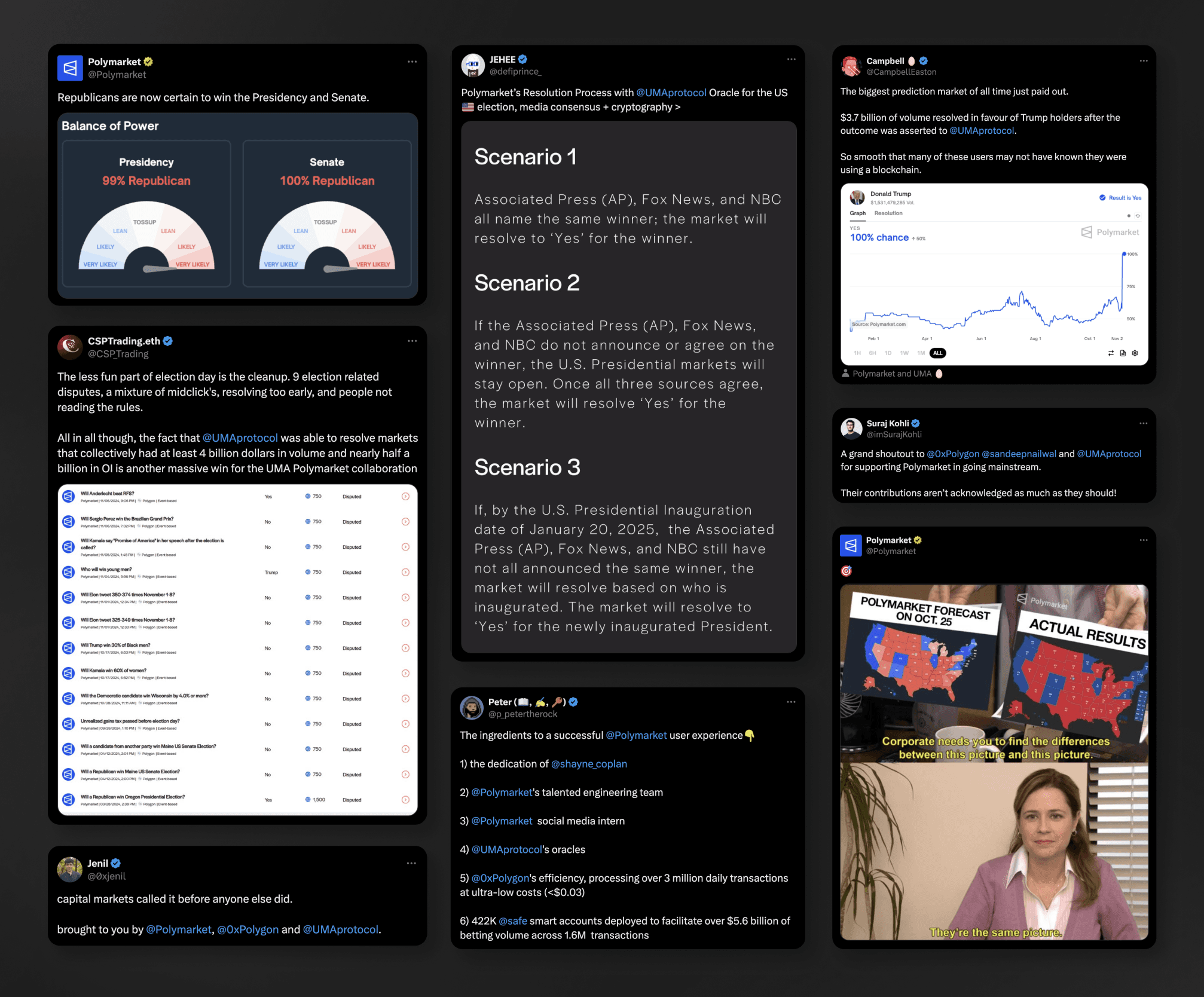
For example, the rise of prediction markets has sparked growing demand for solutions that can reliably verify intersubjective data. With the help of UMA’s oracle, Polymarket recently settled the 2024 US Presidential Election market—the largest prediction market in history.
Several other smaller election markets were disputed and efficiently verified by UMA’s Decentralized Verification Mechanism (DVM), which utilizes consensus-driven verification to settle controversial data assertions (more on this in the sections below). This series of events marked a new era for prediction markets, unlocking deeper utility for intersubjective data verification solutions like UMA.
The trend shows no signs of slowing down, particularly within the Ethereum ecosystem. As Web3 expands, the need for consensus-based data verification will continue to grow across applications where transparent, community-driven validation is crucial.
Other use cases include insurance claim dispute verification, community notes mechanisms (similar to community notes on X), non-arbitrary NFT valuation mechanisms, decentralized content moderation, media fact-checking, and reputation systems implemented in SocialFi ecosystems. UMA’s oracle is purpose-built for these environments, providing a future-proofed solution for any application requiring intersubjective data.
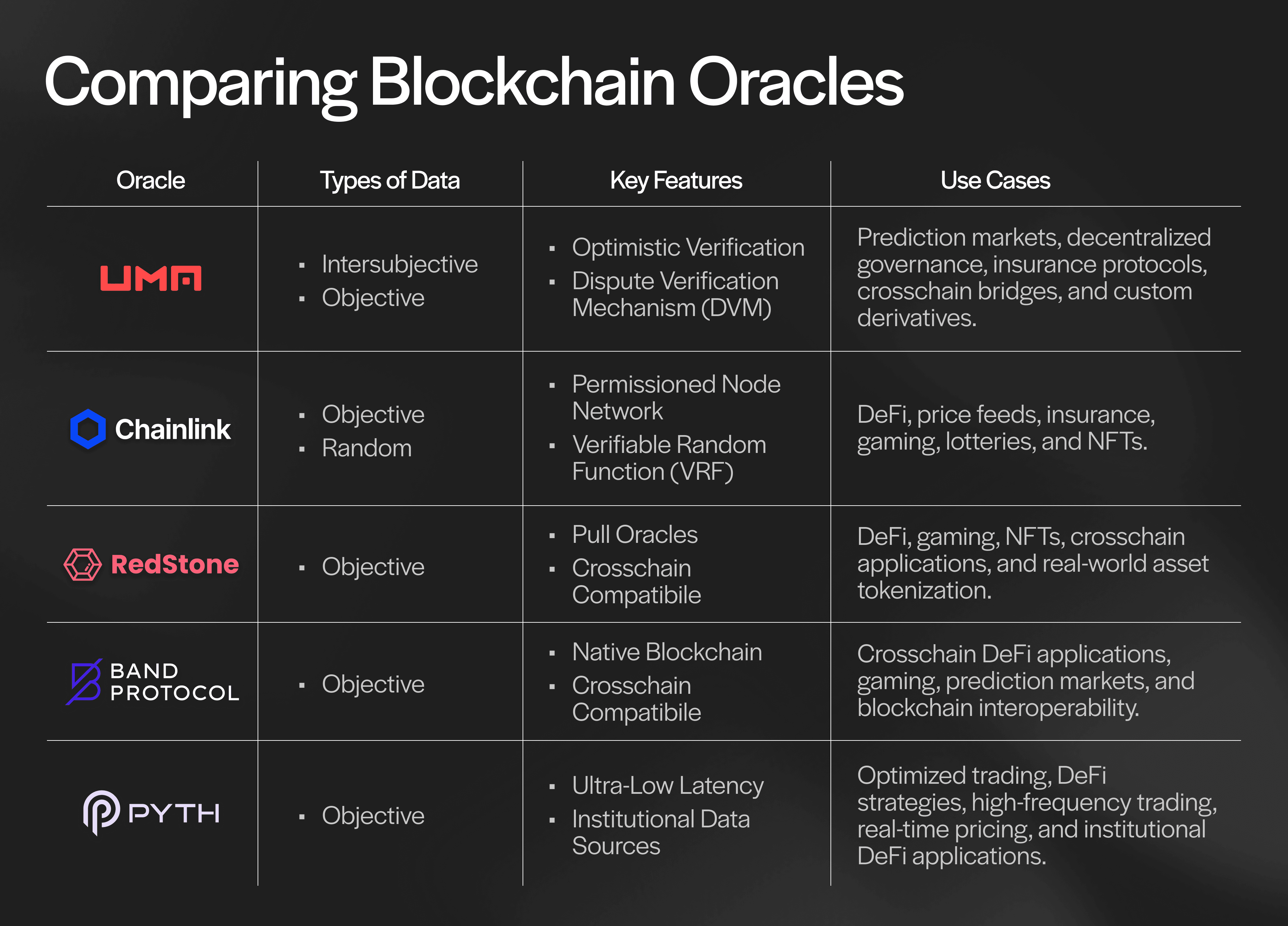
Most Popular Types of Blockchain Oracles in Crypto
There are many types of blockchain oracles and service providers, each specializing in different varieties of data, use cases, and smart contract interaction. With this said, there are five main oracles dominating the space.
Let’s explore each of them, their key features, and main use cases.
UMA
UMA Protocol is a decentralized protocol that provides an optimistic oracle designed to enable trustless and flexible onchain data verification. UMA’s oracle leverages both optimistic verification and consensus-driven data verification, providing a unique model where data is assumed correct until challenged.
Smart contracts can interact with UMA's oracle by requesting specific data points, which UMA verifies through its dispute resolution process. This approach reduces costs by minimizing dispute frequency, making it an efficient and scalable solution for any applications needing community-backed data validation.
Key Features:
Optimistic Verification: Enables fast and low-cost data verification by avoiding disputes unless a challenge is raised. In other words, all data is assumed true unless disputed as false.
Data Verification Mechanism (DVM): A decentralized layer that ensures accuracy of disputes via decentralized, shielded community voting. This approach is particularly suitable for intersubjective data.
Best Suited For:
Intersubjective Data: UMA's Optimistic Oracle is designed to handle data requiring community consensus or interpretation, such as prediction market outcomes and governance decisions.
Objective Data: While optimized for intersubjective data, UMA's oracle can also process objective data, including financial market prices and sports scores, ensuring accuracy through its dispute resolution mechanism.
Use Cases:
Prediction Markets: UMA's oracle enables decentralized platforms to resolve market outcomes based on community consensus, ensuring fair and transparent results. Polymarket is the largest prediction market platform that utilizes UMA’s oracle to verify market outcomes and resolve disputes onchain.
Decentralized Governance: By verifying and executing governance decisions, UMA supports DAOs in implementing proposals securely and efficiently. Over 20 protocols rely on oSnap—a governance tool built on UMA’s oracle—to optimistically verify governance proposals and provide a dispute mechanism for community members. This has empowered these protocols to achieve smoother and more secure governance.
Onchain Security & Insurance: UMA facilitates the creation of decentralized insurance products by verifying claims based on real-world or onchain events, providing a trustless mechanism for payouts. For example, Sherlock offers a small amount of insurance to all teams that use their bug bounties, and payouts are determined by UMA’s oracle. Another example is Cozy Finance, which has safety modules to insure onchain events. They offer UMA’s oracle as an option for triggering payouts.
Crosschain Interoperability: UMA's oracle secures crosschain transactions by validating data across different blockchains, ensuring accurate and reliable transfers. Across Protocol relies on UMA’s oracle as a crosschain interoperability protocol to verify relayer transactions and repayments, serving as a foundational component to the platform’s ability to process and execute crosschain Intents.
Custom Derivatives: Developers can build custom derivatives, synthetic assets, financial contracts, or structured financial products for digital assets using UMA’s oracle to ensure accurate and reliable data feeds.
Chainlink
Chainlink is a leading semi-decentralized oracle network providing secure, real-time data feeds and randomness for crypto, DeFi, gaming, and insurance applications. Unlike fully decentralized solutions, Chainlink's permissioned node network balances decentralization with reliability, reducing risks associated with entirely centralized oracles. Its extensive network of nodes sources data from multiple verified providers, ensuring reliability and tamper-proof delivery. Additionally, Chainlink offers specialized services for unbiased randomness and off-chain task automation, making it a versatile tool for diverse decentralized applications.
Key Features:
Permissioned Node Network: Chainlink’s network of vetted, independent nodes retrieves and verifies data from multiple sources, offering a balance of security and reliability while maintaining a semi-decentralized structure across diverse applications.
Verifiable Random Function (VRF): Chainlink VRF generates tamper-proof randomness, crucial for applications like gaming and lotteries where fair, unpredictable outcomes are needed.
Best Suited For:
Objective Data: Chainlink excels in providing accurate, real-time data feeds, such as financial market prices, weather data, and sports scores. Its decentralized network of nodes ensures data reliability and security.
Random Data: Chainlink's VRF delivers secure and verifiable randomness, essential for applications requiring unbiased random outcomes.
Use Cases:
DeFi: Chainlink provides secure, real-time price feeds crucial for DeFi protocols, enabling functionalities like trading, lending, borrowing, and digital asset management.
Insurance: By supplying reliable weather and real-world data, Chainlink enables decentralized insurance platforms to automate claims and payouts based on actual events.
Gaming and Lotteries: Chainlink's VRF ensures fair and transparent random number generation, vital for gaming applications and lotteries.
NFTs: Chainlink VRF can assign random attributes to NFTs, adding uniqueness and variability to digital collectibles.
RedStone
RedStone is a decentralized oracle network focused on providing fast, cost-efficient, and scalable data feeds. They provide real-time, crosschain data feeds using an innovative off-chain storage approach, enabling cost-efficient, high-frequency data for cryptocurrency, DeFi, gaming, and asset tokenization. Unlike hardware oracles, which rely on physical devices, RedStone leverages off-chain data storage and verification for cost efficiency and scalability.
Key Features:
Pull Oracles: RedStone stores data off-chain but delivers it in a way that enables onchain verification, enabling faster updates with lower gas costs.
Crosschain Compatibility: RedStone’s architecture supports data availability across multiple blockchains, making it an adaptable solution for dApps operating on various chains.
Best Suited For:
Objective Data: RedStone excels in delivering objective data, such as financial prices, commodity information, and other measurable data points.
Use Cases:
DeFi: RedStone’s accurate price feeds are crucial for DeFi applications, supporting trading, lending, borrowing, digital asset management, and more.
Gaming and NFTs: Real-time data delivery benefits gaming and NFT platforms that depend on timely information for in-game assets, pricing updates, and rewards.
Crosschain Applications: RedStone’s data compatibility across multiple chains supports dApps in multi-chain ecosystems, ensuring consistent data access for diverse platforms.
Real-World Asset Tokenization: By providing real-time, accurate data for assets like commodities and stocks, RedStone enables asset tokenization and other real-world asset applications on the blockchain.
Band Protocol
Band Protocol is a crosschain oracle focused on delivering scalable, cost-efficient data across multiple blockchain networks, ideal for multi-chain DeFi and gaming. By operating on its own independent blockchain, Band ensures faster data processing and lower costs compared to other oracle solutions that rely on external infrastructures. Its flexibility allows developers to integrate Band’s data feeds seamlessly into dApps across different ecosystems, making it a versatile option for projects requiring consistent and reliable data in multi-chain environments.
Key Features:
Native Blockchain: Band’s independent blockchain allows for fast and reliable data processing at a lower cost, benefiting applications that require frequent, economical data updates.
Crosschain Compatibility: Band Protocol seamlessly delivers data across various blockchain ecosystems, making it versatile for dApps needing consistent data on multiple networks.
Best Suited For:
Objective Data: Band Protocol specializes in delivering accurate and cost-effective data feeds, particularly for DeFi applications.
Use Cases:
Crosschain DeFi Applications: Band's flexible data solutions are ideal for DeFi applications operating across multiple blockchains, offering consistent and reliable price feeds for digital assets.
Gaming and Prediction Markets: Band supports applications requiring real-time data, such as odds or statistics for prediction markets and in-game assets.
Blockchain Interoperability: Band serves as a bridge for decentralized applications needing uniform data across different blockchain networks, facilitating crosschain transactions and analytics.
Pyth Network
Pyth Network specializes in ultra-low latency financial data, sourced directly from institutions, making it perfect for high-frequency trading and DeFi applications requiring real-time market data. By aggregating data from top-tier financial entities, Pyth ensures unparalleled accuracy and reliability, catering to professional-grade trading platforms. Its focus on minimizing latency makes it an indispensable tool for applications where even slight delays in data can lead to significant market impact, such as derivatives trading and algorithmic strategies.
Key Features:
Ultra-Low Latency: Pyth Network offers near-instantaneous data updates, making it especially valuable for high-frequency trading and DeFi applications where real-time data accuracy is critical.
Institutional Data Sources: Aggregating data directly from institutional contributors, Pyth delivers highly reliable financial information near-instantaneous updates tailored for professional-grade trading and DeFi platforms.
Best Suited For:
Objective Data (Financial Market Data): Pyth specializes in high-frequency financial data, aggregating real-time price information directly from institutional sources, making it ideal for applications requiring low-latency financial data.
Use Cases:
Optimized Trading and DeFi Strategies: By offering ultra-low latency financial data, Pyth enables trading platforms and DeFi protocols to optimize strategies for digital assets, including cryptocurrency and tokenized securities.
High-Frequency Trading: Pyth's ultra-low latency price feeds provide trading platforms with the speed and precision necessary for high-frequency trading strategies.
DeFi Protocols Requiring Real-Time Prices: DeFi platforms that rely on rapid price updates—such as derivatives trading and asset-backed lending—benefit from Pyth's real-time financial data.
Institutional DeFi Applications: Pyth's direct data from institutional sources is valuable for financial products targeting professional investors and platforms needing accurate market data.
Why UMA's Oracle is Uniquely Positioned
While there are several oracle solutions available, UMA’s optimistic oracle stands out due to its innovative approach, technical architecture, and focus on intersubjective data. Unlike traditional oracles that rely on continuous data validation from external sources, UMA’s Optimistic Verification Model assumes data is correct unless disputed. This minimizes the need for constant validation, significantly reducing costs and improving scalability for decentralized applications.
What sets UMA apart even further is its Data Verification Mechanism (DVM), which ensures accuracy through decentralized, community-driven dispute resolution. By leveraging the collective judgment of third-party voters, UMA provides a transparent, reliable, and tamper-proof framework for verifying disputed data in a consensus-driven manner. This makes it ideal for applications like prediction markets, DAO governance, and decentralized insurance, where disputed outcomes often require more nuanced, human oversight. All participants in UMA’s oracle (proposers, disputers, and voters) are economically incentivized to behave truthfully.
UMA’s oracle has established massive dominance in the Ethereum ecosystem, deployed across mainnet and several Layer 2 and EVM-compatible networks including Polygon, Optimism, Arbitrum, Gnosis Chain, Avalanche, Base, Blast, Core, and Boba. You can view the full list of supported networks here.
Get Involved with UMA’s Oracle
UMA’s ecosystem is dynamic, serving use cases across DeFi, prediction markets, a cross chain bridge, insurance protocols, and beyond. The optimistic oracle and DVM offer opportunities for both users and developers. Here’s how you can get involved.
For Users: Participate in the DVM
UMA’s optimistic oracle and DVM empowers users to play an active role in maintaining the oracle’s integrity:
Propose Data: Submit new data proposals for UMA’s oracle to verify. Whether it’s a governance decision or a prediction market outcome, your proposals help transfer real-world data onchain—and you can earn rewards for doing it accurately. (Read the walkthrough here.)
Dispute Incorrect Data: If you believe submitted data is incorrect, raise a dispute during the challenge period. By doing so, you can earn rewards for helping ensure that only accurate data is finalized and published onchain. (Learn how to dispute here.)
Vote on Disputes: Stake $UMA tokens to participate in the voting process and earn rewards for contributing to dispute resolution. (Follow our voting guide here.)
For Developers: Build with UMA’s Oracle
Developers can leverage UMA’s tools to create dApps that require reliable, onchain data. Here’s how you can start:
Integrate the OO into Your Smart Contracts: UMA’s Optimistic Oracle (OO) offers a flexible, cost-efficient framework for interacting with real-world data. Customize parameters like dispute windows and collateral to fit your use case. (Learn how to integrate and build with UMA here.)
Explore Success Stories: See how protocols like Polymarket, Across, and many others use UMA’s oracle to power prediction markets, crosschain bridges, governance tools, and beyond. (Explore examples here.)
Access Developer Resources: UMA provides robust documentation and community support to help you build confidently. (Start building here.)

Closing Thoughts
Oracles are essential for Web3’s growth—they connect blockchains with the real world. By enabling external data to flow onchain, oracles empower dApps to handle complex use cases efficiently, reducing costs and increasing throughput in ways that unlock greater scalability. Decentralized oracles enhance dApp security by mitigating risks of data tampering and single points of failure. This reliability builds user trust by ensuring transparent and fair smart contract operations, making blockchain-based applications dependable and impactful.
The growing importance of intersubjective data represents a transformative opportunity. Beyond prediction markets, intersubjective data verification is paving the way for applications such as community-driven fact-checking, decentralized reputation systems, and citizen journalism. Imagine if governments could use verified community input to determine funding priorities, or if decentralized media platforms could rely on consensus to moderate content fairly and transparently. This is just a peak into what is yet to come.
As Web3 continues to grow, oracles will remain at the core of its success, empowering smart contracts to interact with a world full of complex, real-time, and human-centric information. By leveraging innovative solutions like UMA’s optimistic oracle, the onchain ecosystems can unlock the limitless potential of decentralization.
Oracles aren’t just tools—they are catalysts for the future of information, powering the next generation of user-focused, impactful applications.
Have Questions? Join Our Community
If you have specific questions or need support, join the UMA Discord to connect with our team and other community members.


