
Inside UMA’s Optimistic Truth Bot
TLDR
UMA’s Optimistic Truth Bot (OTB) is an AI agent that shadows human proposers in live prediction markets. Its architecture combines a router, specialized solvers, and an overseer that audits every answer in a feedback loop. The result is a self-correcting system designed to propose accurate, auditable truth without putting capital at risk.
Introduction
Can an LLM-powered agent match human proposers without putting capital at risk?
That’s the question we’re answering with the Optimistic Truth Bot (OTB). The OTB is an AI-powered agent that runs in parallel with human proposers in live prediction markets. It watches Polymarket questions, gathers evidence, classifies outcomes, and runs every decision through a structured feedback loop designed to catch errors before they reach the chain.
This post breaks down how the system works, how it evolved from a single-shot LLM call into a layered architecture of solvers and overseers, and what we have learned so far about building trust-minimized automation for oracle-grade truth.
Why Even Try to Automate a Proposer?
UMA’s optimistic oracle lets anyone propose an answer to data queries. If nobody disputes within a short window, that answer becomes the onchain truth. The protocol’s permissionless design keeps governance simple, but it also means a human must be online, reading markets, and pushing data at the right moment. An AI agent that performs the same grunt work more cheaply, continuously, and under constant human oversight is a compelling proposition.
The Optimistic Truth Bot was spun up in March 2025 to test that idea. It watches Polymarket questions, hunts for evidence, decides between “Yes”, “No”, “50-50”, or “Too Early”, and posts the recommendation on X at @OOTruthBot. For now, the bot only shadows human proposers so every decision can be benchmarked without risking real assets. Readers unfamiliar with UMA can skim the Optimistic Oracle overview for context.
From Single-Shot LLM to Three-Layer Feedback System
The first prototype was a single Perplexity call: ask one big question, get one big answer. Hallucinations slipped through, deterministic markets (BTC closing price, MLB scores) lagged badly, and there was no mechanism to keep the call honest.
Adding an Overseer helped: it validated JSON, date formats, and flagged outputs that contradicted Polymarket prices. Hallucinations dropped, but many markets still failed because Perplexity lacked the right source.
The breakthrough came when a second specialist, Code-Runner, entered the mix. Instead of searching the web, it writes a tiny Python script against Binance for price feeds or SportsData IO for live scores. Direct APIs proved faster and error-free. At that point the Router, Solvers, and Overseer formed a closed loop. The Overseer could reject an answer, attach a structured hint (e.g., “missing citation”, “timezone wrong”, “API threw 500”) and send the request back to the Router, which re-prompts the solver with tighter instructions. If the Overseer says “Too Early”, the whole loop sleeps five minutes and tries again, ensuring that once the data really exists the bot will eventually converge.
Architecture at a Glance
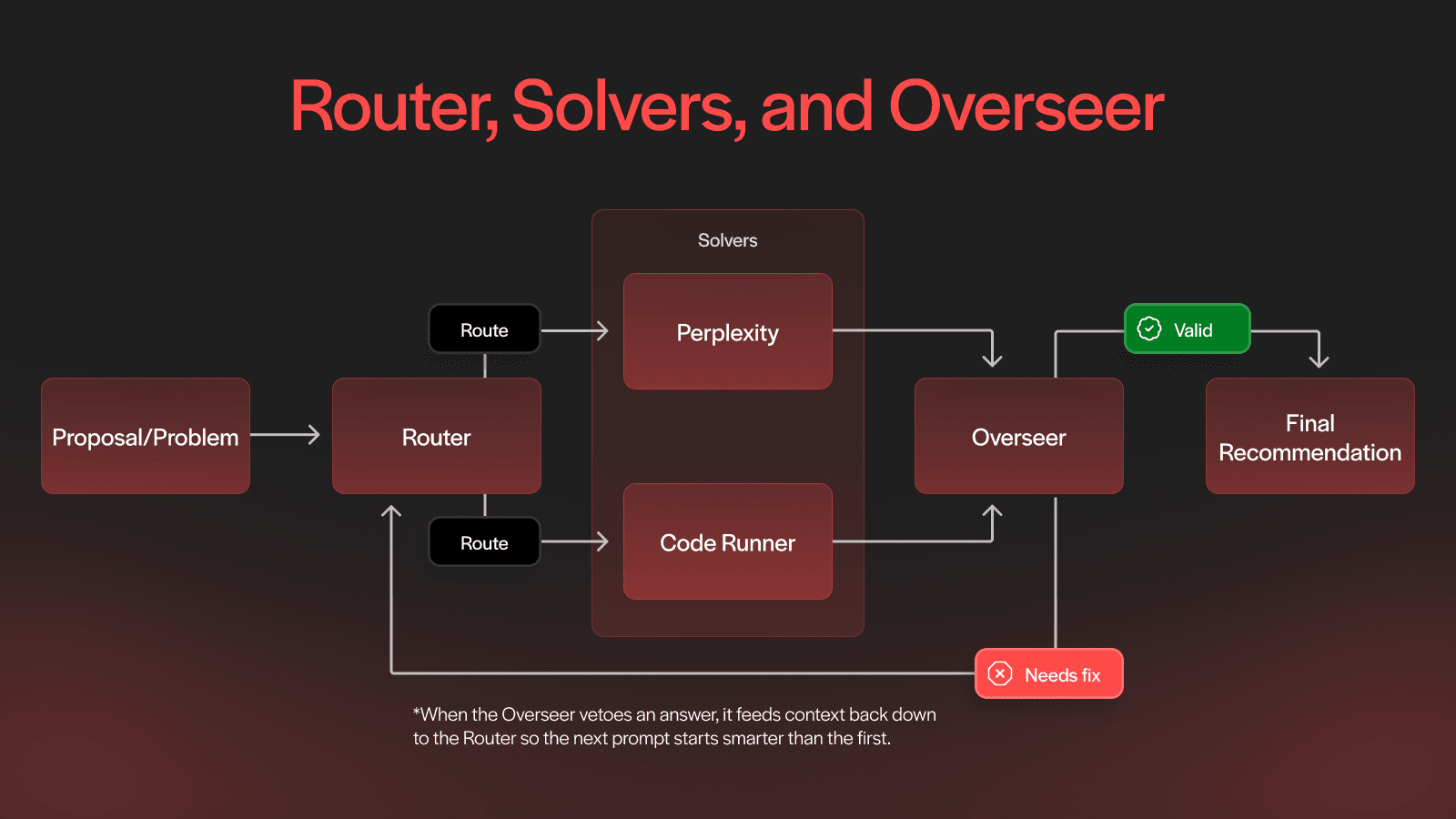
The Three Layers in Depth
Router: Opinionated Dispatcher.
A lightweight classifier (regex + embeddings) tags each proposal as price, sports, or general. Deterministic tags go straight to Code-Runner. Open-ended tags start with Perplexity. Low-confidence tags hit both solvers so the Overseer can arbitrate. The Router tracks solver latencies, error rates, and token costs in real time and always chooses the cheapest viable path. When the Overseer sends a feedback object—{reason, fix_hint, next_timeout}—the Router splices those details directly into the follow-up prompt.
Code-Runner: Deterministic Answers at API Speed.
Templates cover crypto prices and the sports. A Binance script fetches millisecond OHLCV, converts UTC to market-local, and outputs the closing price. A SportsData IO script returns the final score seconds after the last out, buzzer, or goal horn. Each script runs in a 60-second sandbox with memory caps and scoped API keys. Direct APIs remove scraping errors and are typically faster than waiting for a news headline.
Perplexity: Breadth, Citations, and Aggressive Filtering.
Perplexity’s research endpoint can scrape PDFs, blogs, and social media that GPT-4 browsing sometimes misses. The prompt demands a direct answer plus inline citations; a post-filter deletes any sentence without a URL before the reply reaches the Overseer.
Overseer: Skeptical Auditor and Feedback Engine.
First it checks syntax (JSON, ISO dates). Then it evaluates semantics: if Polymarket’s live price implies ≥ 85 % confidence in the opposite outcome, the answer is marked UNSAFE. It then packages a machine-readable hint and either tells the Router to reroute, tighten the prompt, or (after four failed cycles) to mark the market “Too Early” and sleep five minutes. The fun side-effect is that crowd pricing becomes a secondary data-quality filter: a bad tick from Binance or a malformed league feed is caught because the odds look wrong.
Note that the Overseer can veto a solver’s answer while keeping the conversation alive, feeding context back down to the Router so the next prompt starts smarter than the first.
Why Roll Our Own Instead of Importing an Agent Framework?
OpenAI’s Agents SDK, LangGraph, and AutoGen offer beautiful trace UIs and powerful abstractions, but those abstractions hide the levers UMA needs: swapping back-end models, blending Perplexity with GPT-4, sandboxing arbitrary Python, wiring in a five-minute sleep loop, and giving an external price feed veto power. Building the loop from scratch keeps every decision point explicit, diff-able, and auditable. This is essential when mistaken answers move real money.
Two Stubborn Limitations
Knowing when to run: Today the bot triggers only after a human has proposed, using people as a signal that evidence likely exists. Research is underway to monitor Polymarket prices and launch automatically once the odds cross a settle-likely threshold, letting the crowd itself whisper “the data is ready”.
Human latency advantage: Fans in a stadium can propose the final score before any API updates. Until the bot taps lower-latency feeds or gains physical sensors, humans will occasionally win that race.
Where the Experiment Heads Next
This release is a snapshot, not a finish line. Near-term work focuses on plugging in larger context-window models, expanding Code-Runner templates to niche data (e-sports, weather, election filings), and experimenting with probabilistic fusion that fuses multiple solver outputs before Overseer review. Every run logs prompts, costs, and verdicts straight into MongoDB; that telemetry is already guiding the next prompt tweaks and template refactors.
Follow Along
Want to follow the OTB and monitor its recommendations? Watch the live feed:
Live recommendations: https://x.com/OOTruthBot
Public AI results dashboard: https://ai.uma.xyz/
The Optimistic Truth Bot shows that chaining narrow experts under a relentless fact-checker, and letting each layer refine the next, can keep LLM pipelines flexible, self-correcting, and inching toward oracle-grade reliability. Even while humans remain the ultimate safety net.


